Motion Generation from Fine-grained Textual Descriptions

Abstract
The task of text2motion is to generate human motion sequences from given textual descriptions, where the model explores diverse mappings from natural language instructions to human body movements. While most existing works are confined to coarse-grained motion descriptions, e.g., "A man squats.", fine-grained descriptions specifying movements of relevant body parts are barely explored. Models trained with coarse-grained texts may not be able to learn mappings from fine-grained motion-related words to motion primitives, resulting in the failure to generate motions from unseen descriptions. In this paper, we build a large-scale language-motion dataset specializing in fine-grained textual descriptions, FineHumanML3D, by feeding GPT-3.5-turbo with step-by-step instructions with pseudo-code compulsory checks. Accordingly, we design a new text2motion model, FineMotionDiffuse, making full use of fine-grained textual information. Our quantitative evaluation shows that FineMotionDiffuse trained on FineHumanML3D improves FID by a large margin of 0.38, compared with competitive baselines. According to the qualitative evaluation and case study, our model outperforms MotionDiffuse in generating spatially or chronologically composite motions, by learning the implicit mappings from fine-grained descriptions to the corresponding basic motions.
Video
Method
Fine-grained Language-motion Dataset Construction

Our 2-shot prompt instructs LLM to generate fine-grained descriptions while summarizing them into pseudo-codes. We find this method greatly enhances the stability of LLM's generation of new descriptions. With GPT-3.5-turbo-0301, we use the selected prompt to remake HumanML3D into a high-quality language-motion dataset specializing in fine-grained texts, FineHumanML3D. To the best of our knowledge, this is the first large-scale language-motion dataset with fine-grained textual descriptions.
FineMotionDiffuse Text2motion Model
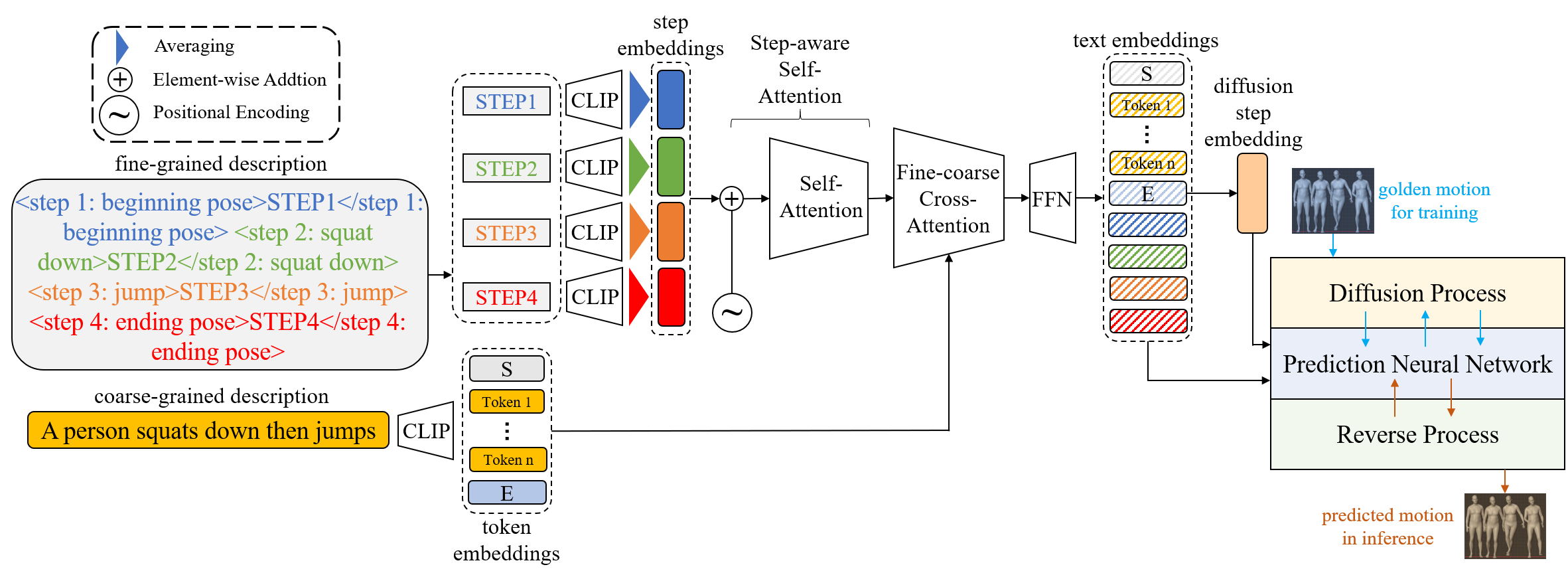
We design a new text2motion model, FineMotionDiffuse, which is composed of a fine-text encoder, a step-aware self-attention block, a coarse-text encoder, a fine-coarse cross-attention block and a diffusion block, to conduct training and inference on FineHumanML3D.
Cases
Spatial Compostionality
The model's ability to simultaneously perform two basic motions.
Coarse-grained: A man raises both arms above his head.
Fine-grained: <step 1: beginning pose>The man begins in a standing position with his arms at his sides.</step 1: beginning pose>
<step 2: raise arms>He lifts both arms up simultaneously, his hands moving upwards towards the ceiling. His shoulders and elbows straighten as his arms reach their maximum height straight above his head.</step 2: raise arms>
<step 3: end pose>He holds this position momentarily before lowering his arms back down to his sides.</step 3: end pose>
Coarse-grained: A person slightly squats.
Fine-grained: <step 1: beginning pose>The man begins standing upright with his feet hip-width apart and his arms relaxed at his sides. </step 1: beginning pose>
<step 2: slight squat>He bends his knees slightly, lowering his hips and shifting his weight slightly towards his heels. His torso remains upright, and his feet remain flat on the ground. </step 2: slight squat>
<step 3: end pose>He holds this slightly squatted position. </step 3: end pose>
Coarse-grained: A man slightly squats with both arms raised above head.
Fine-grained: <step 1: beginning pose>The man begins in a standing position with his feet shoulder-width apart and his arms at his sides.</step 1: beginning pose>
<step 2: squat>He slightly squats down, bending his knees and lowering his hips a few inches towards the ground. His torso remains upright and his arms are raised straight above his head, palms facing each other.</step 2: squat>
<step 3: end pose>He holds this position for a moment before standing back up again to the starting position with his feet shoulder-width apart and arms at his sides.</step 3: end pose>
Chronological Compostionality
The model's ability to perform two basic motions in a temporally sequential manner.
Coarse-grained: A man walks.
Fine-grained: <step 1: beginning pose>The man stands upright with his feet together.</step 1: beginning pose>
<step 2: lift foot>He lifts his left foot off the ground and swings it forward while simultaneously shifting his weight onto his right foot.</step 2: lift foot>
<step 3: place foot>He plants his left foot on the ground and transfers his weight onto it while simultaneously lifting his right foot off the ground.</step 3: place foot>
<step 4: swing foot>He swings his right foot forward while simultaneously shifting his weight onto his left foot, as he prepares to take another step.</step 4: swing foot>
<step 5: end pose>He repeats steps 2-4, alternating between his left and right foot, to continue walking.</step 5: end pose>
Coarse-grained: A man kicks with one leg.
Fine-grained: <step 1: beginning pose>The man begins standing with his feet shoulder-width apart and his arms at his sides.</step 1: beginning pose>
<step 2: lift leg>He lifts one leg, bending at the knee and bringing his foot up towards his buttocks.</step 2: lift leg>
<step 3: extend leg>He then extends his leg forward, kicking with the foot while keeping the rest of his body stable. His arms remain at his sides for balance.</step 3: extend leg>
<step 4: lower leg>After the kick, he lowers his leg back to the ground, returning to his starting position.</step 4: lower leg>
Coarse-grained: A man walks, then kicks with one leg.
Fine-grained: <step 1: beginning pose>The man begins in a standing position with his feet together and his arms at his sides.</step 1: beginning pose>
<step 2: taking a step>He lifts his right foot and takes a step forward with it, placing it on the ground in front of him.</step 2: taking a step>
<step 3: kicking>He then swings his left leg forward in a kicking motion, keeping it straight and extending it towards an imaginary target. As he kicks, he leans his torso back slightly for balance.</step 3: kicking>
<step 4: end pose>He then lowers his left leg back to the ground and resumes the standing position with his feet together and his arms at his sides.</step 4: end pose>
Citation
@inproceedings{li-feng-2024-motion-generation,
title = "Motion Generation from Fine-grained Textual Descriptions",
author = "Li, Kunhang and Feng, Yansong",
booktitle = "Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024)",
month = may,
year = "2024",
address = "Torino, Italy",
publisher = "ELRA and ICCL",
url = "https://aclanthology.org/2024.lrec-main.1016",
pages = "11625--11641"
}